Nghiên cứu phương pháp nhóm các cụm từ thành nhóm bằng phương pháp phân tích nhóm dựa trên đồ thị dendrogram - Ứng dụng nâng cao hiệu quả phân loại tự động văn bản tiếng Việt”. Luận án cũng đề xuất sử dụng phương pháp phân tích cụm bằng đồ thị dendrogram [11 [12] trong việc nhóm các từ tiếng Việt thành các nhóm. Vì vậy, trong chương trình phân loại tiếng Việt, chúng tôi đã sử dụng phương pháp phân nhóm cụm từ xếp tầng để kết hợp các từ tiếng Việt.
Học có giám sát
Phân cụm dựa trên mật độ: Phân cụm dựa trên mật độ nhóm các đối tượng dữ liệu dựa trên một hàm mật độ nhất định, mật độ là số đối tượng liền kề của một đối tượng. Phương pháp này có thể phát hiện các cụm dữ liệu có hình dạng bất kỳ và có thể xử lý rất tốt các giá trị ngoại lệ hoặc nhiễu. Tuy nhiên, việc xác định tham số mật độ cho thuật toán là rất khó khăn, trong khi tham số có ảnh hưởng lớn đến kết quả phân cụm.
Trong 4 phương pháp trình bày ở trên, có thể thấy phương pháp phân lớp theo lớp là phương pháp hợp lý nhất để áp dụng cho việc phân cụm từ tiếng Việt. Hơn nữa, bằng cách hiển thị các đối tượng dưới dạng biểu đồ dendrogram giúp chúng ta có được cái nhìn trực quan hơn về mối tương quan giữa các từ và cụm từ.
Học bán giám sát
Học bán giám sát[17] [21] là học với tập dữ liệu bao gồm cả dữ liệu được gắn nhãn và không được gắn nhãn. Tùy thuộc vào mục đích cụ thể, học bán giám sát có thể được áp dụng cho các bài toán phân loại hoặc phân cụm.
Học tăng cường
PHƯƠNG PHÁP PHÂN CỤM DENDROGRAM
Phương pháp lân cận dài nhất: Khoảng cách giữa hai nhóm được tính bằng khoảng cách lớn nhất trong số tất cả các cặp dữ liệu thuộc hai nhóm khác nhau. Phương pháp trung bình nhóm: Khoảng cách giữa hai nhóm được tính bằng khoảng cách trung bình của tất cả các cặp dữ liệu thuộc hai nhóm khác nhau. Phương pháp trọng tâm: Khoảng cách giữa hai nhóm được tính bằng khoảng cách trọng tâm của hai nhóm.
Phương pháp bộ phận: Khoảng cách giữa hai nhóm được tính bằng tổng bình phương khoảng cách của tất cả các cặp dữ liệu thuộc hai nhóm khác nhau. Nếu dữ liệu được biểu diễn bằng vectơ hoặc điểm trong không gian Euclide thì chúng ta có thể sử dụng khoảng cách Euclide hoặc khoảng cách Minkowski để tính toán. Đối với văn bản, chúng ta cũng có thể tính toán khoảng cách dựa trên hệ số tương quan, cấu trúc câu và ngữ nghĩa của hai văn bản.
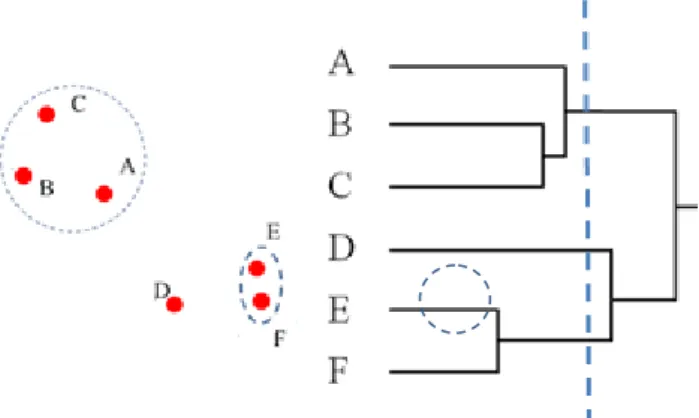
Luận án này sử dụng xác suất xuất hiện đồng thời trong văn bản để tính khoảng cách giữa hai từ trong tiếng Việt. Ta thấy “E” và “F” có khoảng cách nhỏ nhất nên được nhóm thành một nhóm gồm hai phần tử.
CÁC PHƯƠNG PHÁP PHÂN LOẠI .1 Phân tích biệt thức tuyến tích
Máy vector hỗ trợ
Các nhóm nhỏ được tạo thành các nhóm lớn hơn bằng cách kết hợp các nhóm nhỏ. Kết quả là tất cả các đối tượng cuối cùng được kết hợp thành một nhóm. Trên cơ sở giới thiệu và phân tích ưu nhược điểm của các phương pháp học máy, chúng tôi lựa chọn phương pháp học máy vectơ hỗ trợ có giám sát (SVM) dựa trên phương pháp phân cụm từ đồ thị Dendrogram và Wikipedia để phân tích kiểu văn bản tiếng Việt.
Kết quả phân cụm từ đồ thị Dendrogram và Wikipedia được sử dụng để thu gọn vectơ đặc trưng của máy vectơ hỗ trợ (SVM).
CẤU TRÚC HỆ THỐNG
CÁC CHỨC NĂNG CHÍNH
Tương tự, chúng ta chỉ cần di chuyển vị trí cắt sẽ có kết quả phân nhóm khác nhau. Người dùng có thể lựa chọn mô hình phân loại trước khi phân loại văn bản thành hai mô hình chính: SVM và SVM gợi ý. Với SVM, mô hình đề xuất sử dụng SVM sử dụng kết quả phân cụm từ tiếng Việt.
Kết quả phân cụm từ tiếng Việt được sử dụng để rút gọn vectơ thuộc tính. Như vậy, mô hình SVM được đề xuất ở đây là sử dụng SVM với các vectơ thuộc tính đã được giảm kích thước, tốc độ giảm tương ứng với tốc độ đạt được khi cắt đồ thị Dendrogram. Tính năng này giúp người dùng tự động phân loại văn bản tiếng Việt từ mô hình phân loại được xây dựng trước đó.
PHÂN TÍCH THIẾT KẾ CHƯƠNG TRÌNH 1. Mô hình use case
CÁC THUẬT TOÁN ĐỀ XUẤT CHÍNH
- Xử lý dữ liệu Wikipedia
- Tính toán ma trận tần số xuất hiện chung
- Tổ chức dữ liệu trong chương trình Dữ liệu trong chương trình bao gồm
- Thư viện hỗ trợ
Xây dựng đồ thị dendrogram để rút gọn vectơ thuộc tính khi xây dựng mô hình phân loại bằng SVM. Với tần suất xuất hiện chung là tổng số trang (đoạn, câu) Wikipedia xuất hiện ở cả từ và trong từ điển. Theo đó, xác suất xuất hiện đồng thời trong tập hợp chứa tất cả các trang (đoạn, câu) có ít nhất một trong hai từ.
Bước 1: Khởi tạo ma trận w để biểu thị xác suất xuất hiện cùng nhau của các cặp từ và trên cùng một trang, đoạn hoặc câu trong Wikipedia tiếng Việt. Tìm phần tử lớn nhất trong w đại diện cho xác suất xuất hiện cao nhất của cặp từ x và y trong đó có ít nhất một từ không được đánh dấu. Bởi vì dữ liệu lớn nên việc tính toán ma trận số lần xuất hiện phổ biến của các từ trong một câu, một đoạn văn hoặc một trang Wikipedia sẽ rất tốn kém.
Máy tính ma trận này đa luồng để tăng tốc độ tính toán. Chương trình tính toán ma trận còn có chức năng tự động lưu kết quả trong quá trình tính toán để tránh tình trạng mất điện hoặc sự cố bất ngờ.
KẾT QUẢ THỰC NGHIỆM
Kết quả phân loại dựa trên tần số xuất hiện chung của các cặp từ trên cùng một trang Wikipedia
- Kết quả phân loại văn bản
Tuy nhiên, các từ này được nhóm chính xác thành một nhóm, điều này chứng tỏ phương pháp đề xuất đã phân cụm thành công các câu có liên quan chặt chẽ. Chúng ta có thể dễ dàng nhận thấy các nhóm từ được nhóm thành các chủ đề. Trong kết quả thử nghiệm, chúng tôi chọn ngẫu nhiên 1.000 nhóm từ và đếm thủ công số nhóm từ đồng nghĩa đúng.
Nó cũng tiết lộ một số cụm từ bao gồm danh từ, động từ và tính từ cho một chủ đề. Ngoài ra, trong tiếng Việt có rất nhiều từ, cụm từ không có trong từ điển mà tác giả sử dụng như “ca chon”, “ca chao”. Hơn nữa, báo cáo này chỉ giới hạn ở các trang Wikipedia nên không thể tiết lộ hết các từ và cụm từ liên quan trong tiếng Việt.
Phân cụm tiếng Việt dẫn đến giảm số chiều của không gian vectơ thuộc tính văn bản, từ đó làm giảm dung lượng lưu trữ của không gian vectơ mẫu. Báo cáo thực hiện việc huấn luyện mô hình phân loại dựa trên hai bộ mẫu được dán nhãn. Thời gian trung bình để phân loại một văn bản phụ thuộc vào số lượng từ được thu thập.
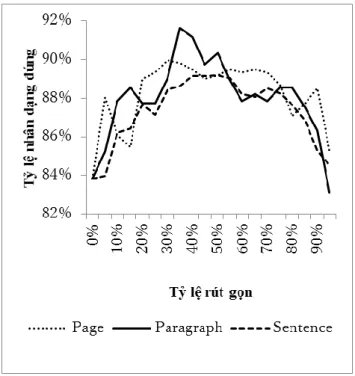
Kết quả so sánh phân cụm sử dụng tần suất xuất hiện phổ biến trên cùng một trang, đoạn văn và câu Wikipedia.
Kết quả so sánh phân cụm sử dụng tần số xuất hiện chung trên cùng một trang, một đoạn và một câu Wikipedia
Từ Hình 30, 31 và 32 chúng ta thấy rằng khi tần suất chung của các cặp từ được sử dụng trên cùng một trang, đoạn văn hoặc câu có xu hướng tăng lên khi chúng ta chọn tỷ lệ giảm thích hợp. Đặc biệt, việc sử dụng tần suất chung của các cặp từ trong cùng một đoạn văn sẽ cho kết quả tốt hơn so với trang hoặc câu.
Hình ảnh DEMO chương trình
Theo kết quả đạt được, chúng tôi đã hoàn thành mục tiêu đặt ra của đề tài “Nghiên cứu phương pháp phân nhóm cụm từ bằng phương pháp phân tích nhóm dựa trên đồ thị dendrogram - Ứng dụng nâng cao hiệu quả phân loại văn bản”. bản tiếng việt tự động. Bằng việc nghiên cứu các phương pháp học máy, luận án này đề xuất hai phương pháp nhằm nâng cao chất lượng phân loại tự động văn bản tiếng Việt. Phương pháp thứ nhất sử dụng bách khoa toàn thư Wikipedia và đồ thị Dendrogram để phân nhóm các từ tiếng Việt.
Phương pháp thứ hai là giảm vectơ thuộc tính trong mô hình SVM bằng kết quả phân cụm được đề xuất. Thực nghiệm cho thấy việc áp dụng không gian vectơ rút gọn bằng Dendrogram và Wikipedia giúp tiết kiệm không gian lưu trữ và thời gian phân loại văn bản tiếng Việt mà vẫn đảm bảo tỷ lệ phân loại chính xác. Với mức giảm 30%-70% so với không gian vectơ ban đầu, tỷ lệ phân loại văn bản đúng cao hơn so với không phân cụm.
Các thí nghiệm so sánh cũng cho thấy việc sử dụng tổng tần suất các từ trên một đoạn văn sẽ tốt hơn trên một trang và một câu. Nó chỉ kiểm tra khả năng xuất hiện thường xuyên của các cặp từ trên một trang Wikipedia để kết hợp các từ, dẫn đến khả năng sai lệch ngữ nghĩa nếu trang Wikipedia có quá nhiều thông tin.