Cây quyết định có thể xử lý tốt lượng lớn dữ liệu trong thời gian ngắn. Vì vậy, nhiệm vụ của thuật toán ID3 là học cây quyết định từ một tập các mẫu huấn luyện, còn được gọi là dữ liệu huấn luyện. Kết quả: Cây quyết định có thể phân loại chính xác các mẫu trong tập dữ liệu huấn luyện và hy vọng cũng phân loại chính xác các mẫu trong tương lai.
Các nút lá biểu thị sự phân loại của các mẫu thuộc nhánh đó hoặc giá trị của thuộc tính phân loại. Khi thuật toán đã tạo ra cây quyết định, cây này sẽ được sử dụng để phân loại tất cả các ví dụ hoặc trường hợp trong tương lai. Đối với một tập dữ liệu huấn luyện sẽ có nhiều cây quyết định có thể phân loại chính xác tất cả các mẫu trong tập dữ liệu huấn luyện.
Vậy làm thế nào chúng ta có thể học một cây quyết định có thể phân loại chính xác tất cả các mẫu trong tập huấn luyện? Với cách tiếp cận này, có thể cây quyết định sẽ không phân loại chính xác các trường hợp mà chúng ta chưa gặp phải trong tương lai. Trong trường hợp này, các thuật toán học cố gắng tạo ra cây quyết định nhỏ nhất để phân loại chính xác tất cả các mẫu đã cho.
Đặt vào phân vùng V các ví dụ trong example_group có giá trị V trong thuộc tính P;.
Thuộc tính nào là thuộc tính dùng để phân loại tốt nhất?
- Entropy đo tính thuần nhất của tập ví dụ
- Lƣợng thông tin thu đƣợc đo mức độ giảm entropy mong đợi
- Tìm kiếm không gian giả thuyết trong ID3
- Đánh giá hiệu suất của cây quyết định
- Chuyển cây về các luật
- Khi nào nên sử dụng ID3
Entropy(S) = 1 tập ví dụ S có các ví dụ thuộc nhiều loại khác nhau có độ trộn cao nhất. Entropy là thước đo hỗn hợp của một tập hợp các ví dụ, bây giờ chúng ta sẽ xác định thước đo hiệu suất phân loại các ví dụ trên một thuộc tính. Biện pháp này được gọi là độ lợi thông tin, đơn giản là mức giảm entropy dự kiến gây ra bằng cách phân vùng các ví dụ theo thuộc tính này.
Trong đó Values(A) là tập hợp các giá trị có thể có của thuộc tính A và Sv là tập con của S chứa các ví dụ trong đó thuộc tính A có giá trị v. Quay lại ví dụ ban đầu, nếu Entropy không được sử dụng để xác định tính đồng nhất của ví dụ, cây quyết định có thể có chiều cao lớn. Chúng tôi áp dụng phương pháp tính toán Entropy để xác định chắc chắn thuộc tính nào được chọn trong khi tạo cây quyết định.
Không gian giả thuyết mà ID3 yêu cầu là một tập hợp các cây quyết định có thể. ID3 thực hiện tìm kiếm từ đơn giản đến phức tạp, theo thuật toán leo đồi, bắt đầu bằng một cây trống, sau đó dần dần xem xét các giả thuyết phức tạp hơn để có thể phân loại chính xác các đối tượng. Ví dụ huấn luyện. Không gian cây quyết định giả định của ID3 là không gian đầy đủ của cây quyết định trên các thuộc tính được đưa ra trong tập huấn luyện.
Do đó, thuật toán này không thể biểu diễn tất cả các cây quyết định khác nhau để có thể phân loại chính xác dữ liệu có sẵn. Vì ID3 sử dụng tất cả các ví dụ ở mỗi bước để đưa ra quyết định dựa trên thống kê nên rất khó có khả năng kết quả tìm kiếm của ID3 sẽ bị ảnh hưởng bởi một vài dữ liệu sai (hoặc nhiễu). Cây quyết định do ID3 tạo ra được coi là tốt nếu cây này có thể phân loại chính xác các trường hợp hoặc ví dụ sẽ gặp trong tương lai, hay cụ thể hơn là có thể phân loại chính xác các ví dụ. không có trong tập dữ liệu huấn luyện.
Để đánh giá hiệu năng của cây quyết định, người ta thường sử dụng một tập mẫu riêng biệt, khác với tập dữ liệu huấn luyện để đánh giá khả năng phân loại của cây dựa trên các ví dụ của tập này. Thông thường, tập dữ liệu có sẵn được chia thành hai tập: tập huấn luyện thường chiếm 2/3 số mẫu và tập kiểm tra chiếm 1/3 số mẫu. Ví dụ: cây quyết định cho tập dữ liệu huấn luyện có thể được chuyển đổi thành một bộ quy tắc như sau.
Tập dữ liệu huấn luyện ở đây bao gồm các ví dụ được mô tả theo cặp. Tuy nhiên, không giống như một số thuật toán khác cũng thuộc phương pháp này, ID3 sử dụng các ví dụ huấn luyện ở dạng xác suất, điều này mang lại lợi thế là ít bị ảnh hưởng bởi một số dữ liệu nhiễu.
Ví dụ minh họa .1 Phát biểu bài toán
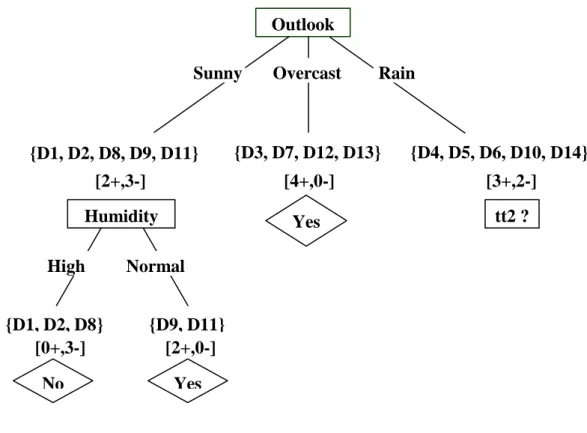
Chúng tôi thấy rằng giá trị Gain(S, Outlook) là lớn nhất nên Outlook được chọn làm thuộc tính kiểm tra. Ta thấy giá trị Gain(SSunny, Humidity) là lớn nhất nên Humidity được chọn làm thuộc tính kiểm tra. Ta thấy giá trị Gain(SRain, Wind) là lớn nhất nên Wind được chọn làm thuộc tính test.