ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
Phạm Đình Phong
PHÁT TRIỂN MỘT SỐ PHƯƠNG PHÁP THIẾT KẾ HỆ PHÂN LỚP TRÊN CƠ SỞ LÝ THUYẾT TẬP MỜ
VÀ ĐẠI SỐ GIA TỬ
Chuyên ngành: Khoa học máy tính Mã số: 62 48 01 01
TÓM TẮT LUẬN ÁN TIẾN SĨ KHOA HỌC MÁY TÍNH
Hà Nội – 2017
Công trình được hoàn thành tại: Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
Người hướng dẫn khoa học: GS. TS. Nguyễn Thanh Thủy PGS. TSKH. Nguyễn Cát Hồ
Phản biện: TS. Nguyễn Công Điều
Viện Công nghệ thông tin, Viện Hàn lâm KH&CN VN Phản biện: TS. Dương Thăng Long
Viện Đại học mở Hà Nội Phản biện: PGS. TS. Nguyễn Đình Hóa
Viện Công nghệ thông tin, Đại học Quốc gia Hà Nội
Luận án sẽ được bảo vệ trước Hội đồng cấp Đại học Quốc gia chấm luận án tiến sĩ họp tại phòng 212, nhà E3, trường Đại học Công nghệ, Đại học Quốc gia Hà Nội, 144 Xuân Thủy, Cầu Giấy, Hà Nội vào hồi 14 giờ 00 ngày 22 tháng 09 năm 2017.
Có thể tìm hiểu luận án tại:
- Thư viện Quốc gia Việt Nam
- Trung tâm Thông tin - Thư viện, Đại học Quốc gia Hà Nội
MỞ ĐẦU
Bài toán phân lớp thường gặp trong các lĩnh vực khác nhau của đời sống xã hội như bao gồm y tế, kinh tế, nhận dạng lỗi, xử lý ảnh, xử lý dữ liệu văn bản, lọc dữ liệu Web, loại bỏ thư rác, … Có nhiều hệ phân lớp quan trọng đã được đề xuất như hệ phân lớp thống kê, mạng nơ-ron, phân lớp dựa trên luật ngôn ngữ mờ, …
Hầu hết các kỹ thuật phân lớp thống kê đều dựa trên lý thuyết quyết định Bayesian có hiệu huất phân lớp phụ thuộc vào mô hình xác suất. Hệ phân lớp mạng nơ-ron cần một lượng lớn các tham số cần phải ước lượng. Mặt khác, kỹ thuật phân lớp thống kê và mạng nơ-ron là những hộp đen nên thiếu tính dễ hiểu đối với người sử dụng. Hệ phân lớp dựa trên luật ngôn ngữ mờ (FLRBC) được nghiên cứu rộng rãi do người dùng cuối có thể sử dụng những tri thức dạng luật được trích rút từ dữ liệu có tính dễ hiểu, dễ sử dụng đối với con người như là những tri thức của họ. Tiếp cận lý thuyết tập mờ không vận dụng các từ ngôn ngữ nhằm truyền đạt ngữ nghĩa của các từ do thiếu một cầu nối hình thức giữa các từ với các tập mờ tương ứng. Đại số gia tử (ĐSGT) cung cấp một cơ chế hình thức sinh các tập mờ từ ngữ nghĩa vốn có (inherent sematic) của các từ ngôn ngữ và ứng dụng một cách hiệu quả vào quá trình thiết kế tập giá trị ngôn ngữ cùng với ngữ nghĩa tính toán dựa trên tập mờ tam giác của chúng cho bài toán xây dựng tự động cơ sở luật cho FLRBC.
Trong ứng dụng lý thuyết tập mờ thường đòi hỏi lõi của tập mờ là một khoảng do ngữ nghĩa của từ ngôn ngữ chứa một miền có giá trị phù hợp với ngữ nghĩa của từ nhất. Ngữ nghĩa dựa trên tập mờ của các từ ngôn ngữ được xem là dạng hạt (granule) và có lõi (core). Như vậy, ngữ nghĩa của mỗi từ ngôn ngữ đều có lõi và được gọi là lõi ngữ nghĩa (semantics core). Trong xu thế nghiên cứu ĐSGT, một cơ sở hình thức toán học cần được phát triển để sinh lõi khoảng của tập mờ biểu diễn ngữ nghĩa của từ ngôn ngữ. Luận án nghiên cứu trường hợp cụ thể sinh lõi khoảng của tập mờ hình thang do lõi của hình thang có dạng khoảng nên chúng có thể được sử dụng để biểu diễn lõi ngữ nghĩa được biểu thị bằng tập mờ của các từ ngôn ngữ. Mặt khác, vấn đề tối ưu các tham số ngữ nghĩa, sinh luật và tìm kiếm hệ luật tối ưu vẫn cần những nghiên cứu cải tiến.
Mục tiêu đặt ra của luận án: Thứ nhất là mở rộng ĐSGT để làm cơ sở hình thức toán học cho việc sinh lõi của các tập mờ gán cho các từ ngôn ngữ, cụ thể là lõi của tập mờ
hình thang và ứng dụng giải bài toán thiết kế tự động cơ sở luật cho hệ phân lớp dựa trên luật ngôn ngữ mờ. Thứ hai là nghiên cứu thiết kế hiệu quả hệ phân lớp dựa trên luật ngôn ngữ mờ với ngữ nghĩa tính toán của từ ngôn ngữ được xác định dựa trên ĐSGT dựa trên kỹ thuật tính toán mềm.
Với các mục tiêu đặt ra của luận án, các đóng góp của luận án là:
Đề xuất mở rộng lý thuyết đại số gia tử biểu diễn lõi ngữ nghĩa của các từ ngôn ngữ nhằm cung cấp một cơ sở hình thức cho việc sinh tự động ngữ nghĩa tính toán dựa trên tập mờ có lõi là một khoảng của khung nhận thức ngôn ngữ. Luận án nghiên cứu trường hợp cụ thể là ngữ nghĩa dựa trên tập mờ hình thang.
Ứng dụng lõi ngữ nghĩa và ngữ nghĩa tính toán dựa trên tập mờ hình thang của khung nhận thức ngôn ngữ giải bài toán thiết kế tối ưu FLRBC đảm bảo tính giải
nghĩa được (interpretability) của chúng. So sánh đánh giá kết quả của các đề xuất so với một số kết quả được công bố trước đó.
Nghiên cứu các yếu tố ảnh hưởng đến hiệu quả của các phương pháp thiết kế FLRBC với ngữ nghĩa tính toán của từ ngôn ngữ được xác định dựa trên ĐSGT và đề xuất giải pháp nâng cao hiệu quả thiết kế FLRBC bằng kỹ thuật tính toán mềm.
Các nội dung và kết quả nghiên cứu được trình bày trong luận án đã được công bố trong 8 công trình khoa học, bao gồm: 1 bài báo quốc tế trong danh mục SCI; 3 bài báo ở Tạp chí Tin học và Điều khiển học; 1 bài báo ở Tạp chí khoa học, Đại học Quốc gia Hà Nội; 1 bài báo ở Tạp chí Khoa học và Công nghệ, Viện Hàn Lâm Khoa học và Công nghệ
Việt Nam; 1 báo cáo trong kỷ yếu hội nghị quốc tế có phản biện được xuất bản bởi IEEE và 1 báo cáo tại hội nghị quốc gia có phản biện.
Cấu trúc của luận án. Luận án được bố cục thành các phần: Mở đầu, 3 chương, kết luận, tài liệu tham khảo và các phụ lục.
Chương 1 giới thiệu tổng quan về hệ dựa trên tri thức luật ngôn ngữ mờ và ĐSGT và khả năng ứng dụng của ĐSGT. Chương 2 trình bày phương pháp mở rộng lý thuyết ĐSGT nhằm cung cấp một cơ sở hình thức sinh lõi ngữ nghĩa và ngữ nghĩa tính toán dựa trên tập mờ hình thang của khung nhận thức ngôn ngữ và ứng dụng trong thiết kế hệ dựa trên tri thức luật ngôn ngữ mờ cho bài toán phân lớp. Chương 3 trình bày đề xuất thiết kế hiệu quả FLRBC với ngữ nghĩa tính toán của từ ngôn ngữ được xác định dựa trên ĐSGT bằng kỹ thuật tính toán mềm.
CHƯƠNG 1
TỔNG QUAN VỀ HỆ DỰA TRÊN TRI THỨC LUẬT NGÔN NGỮ MỜ 1.1. MỘT SỐ KHÁI NIỆM CƠ BẢN
1.1.1. Tập mờ
1.1.2. Biến ngôn ngữ 1.1.3. Phân hoạch mờ
1.1.4. Luật ngôn ngữ mờ và hệ luật ngôn ngữ mờ
Luật ngôn ngữ mờ hay luật mờ if-then, được gọi tắt là luật mờ, là một phát biểu có điều kiện dưới dạng if A then B. Phần if của luật được gọi là giả thuyết hay tiền đề luật, phần then của luật được gọi là phần kết luận.
1.1.5. Bài toán phân lớp dữ liệu
Bài toán phân lớp dữ liệu P được phát biểu như sau: cho một tập dữ liệu mẫu D = {(dp, Cp), p = 1, …, m}, trong đó m là số mẫu dữ liệu, dp = [dp,1, dp,2, ..., dp,n] là dòng thứ p trong m mẫu dữ liệu có n thuộc tính, C = {Cs | s = 1, …, M} là một tập gồm M nhãn lớp.
Quá trình xây dựng mô hình phân lớp thường được chia thành hai bước:
Bước 1. Huấn luyện: mô hình phân lớp được xây dựng dựa trên các tập dữ liệu mẫu đã được gán nhãn, được gọi là các tập dữ liệu huấn luyện.
Bước 2. Thử nghiệm mô hình: sử dụng mô hình đã được xây dựng tại bước 1 để phân lớp tập dữ liệu mới đã được gán nhãn được chọn ngẫu nhiên và độc lập với tập dữ liệu huấn luyện.
1.2. HỆ DỰA TRÊN TRI THỨC LUẬT NGÔN NGỮ LUẬT MỜ 1.2.1. Cấu trúc của hệ dựa trên luật ngôn ngữ mờ
Hệ dựa trên luật ngôn ngữ mờ bao gồm hai thành phần chính: cơ sở tri thức và hệ suy luận. Cơ sở tri thức bao gồm cơ sở dữ liệu và cơ sở luật. Cơ sở dữ liệu bao gồm tập các giá trị ngôn ngữ được dùng trong biểu diễn cơ sở luật và các hàm thuộc biểu diễn ngữ nghĩa của các giá trị ngôn ngữ. Cơ sở luật là tập hợp các tri thức liên quan đến các bài toán cần giải quyết dưới dạng các luật mờ if-then.
1.2.2. Bài toán thiết kế hệ phân lớp dựa trên luật ngôn ngữ mờ Hệ các luật mờ phân lớp bao gồm một tập luật mờ có trọng số dạng:
Luật Rq: if X1 is Aq,1 and ... and Xn is Aq,n then Cq with CFq, với q=1..N (1.1) trong đó X = {Xj, j = 1, .., n} là tập n biến ngôn ngữ (thuộc tính) và Aq,j (j=1, ..., n) là các giá trị ngôn ngữ của các điều kiện mờ trong tiền đề, Cq là nhãn lớp kết luận của Rq và N là số luật mờ, CFq là trọng số hay độ tin cậy của luật thứ q. Luật Rq có thể được viết tắt dưới dạng Aq⟹Cq with CFq, trong đó Aq là tiền đề của luật thứ q.
Ký hiệu fp(S), fn(S) và fa(S) lần lượt là hàm đánh giá độ chính xác phân lớp của hệ S đối với tập dữ liệu huấn luyện, số luật trong hệ S và độ dài trung bình hệ S. Khi đó, mục tiêu xây dựng hệ phân lớp thỏa các mục tiêu:
fp(S) → max, fn(S) → min và fa(S) → min. (1.2) Các mục tiêu trên mâu thuẫn nhau nên các phương pháp giải bài toán phân lớp dựa trên luật mờ phải cân bằng các mục tiêu trên.
Các bước của bài toán thiết kế FLRBC theo tiếp cận lý thuyết tập mờ bao gồm:
Bước 1. Phân hoạch miền giá trị của các thuộc tính của tập dữ liệu thành các vùng mờ
sử dụng các tập mờ tương ứng với các từ ngôn ngữ của biến ngôn ngữ.
Bước 2. Trích rút các luật mờ từ các phân hoạch mờ được tạo ở bước 1 sao cho hệ luật mờ S thu được nhỏ gọn, dễ hiểu và có hiệu suất phân lớp cao.
Hai phương pháp phân hoạch mờ thường được sử dụng là phân hoạch lưới và phân hoạch rời rạc. Các thước đo đánh giá luật dựa trên độ tin cậy (confidence) và độ hỗ trợ (support) làm tiêu chuẩn sàng để sàng lọc ra các luật ứng viên:
c(Aq⟹Cq)=
p∈Class C
∑
qμAq(dp)
∑
p=1 mμAq(xp)
. (1.3)
s(Aq⟹Cq)=
p∈Class C
∑
qμAq(dp)
m . (1.4)
trong đó μAq(dp) là độ tương thích hay độ đốt cháy của mẫu dữ liệu dp đối với điều kiện Aq của luật Rq và thường được tính bằng biểu thức toán tử nhân như sau:
μAq(dp)=
∏
i=1 n
μAq , j
i, j(dp , ji). (1.5)
- Độ tin cậy (c), độ hỗ trợ (s) và tích (c × s) đều có thể dùng làm tiêu chuẩn sàng.
- Nhãn lớp của từng điều kiện tiền đề Aq được xác định như sau:
Cq=argmax{c(Aq⇒Ch)∨h=1,… , M} . (1.6) - Các luật có thể được gán trọng số luật, công thức sau thường được sử dụng:
CFqIII
=c(Aq⟹Cq)−cq ,2nd, (1.9) cq,2nd là độ tin cậy lớn nhất của các luật có cùng điều kiện Aq nhưng khác kết luận khác Cq.
cq ,2nd=max
{
c(Aq⟹Clas s h)∨h=1, … , M ;h ≠ Cq}
, (1.12)Hai phương pháp lập luận phân lớp cho một mẫu dữ liệu dp = [dp,1, dp,2, ..., dp,n]:
- Phương pháp lập luận là Single Winner Rule:
μAw(dp)× CFw=argmax(μAq(dp)×CFq
|
Rq∈S). (1.14) - Phương pháp lập luận bầu cử có trọng số (weighted vote):VClassh(dp)=argmax
(
RC∑
qq∈S=hμAq(dp)×CFq,h=1, … M
)
. (1.15)1.2.3. Những vấn đề tồn tại
- Hầu hết các đề xuất theo hướng tiếp cận lý thuyết tập mờ vẫn thiếu một cơ chế hình thức liên kết giữa ngữ nghĩa vốn có của các từ ngôn ngữ với các tập mờ tương ứng của chúng; thiếu một cơ sở hình thức hóa toán học trong thiết kế tự động ngữ nghĩa tính toán dựa trên tập mờ từ ngữ nghĩa vốn có của các từ ngôn ngữ, dẫn đến hệ phân lớp thu được không là kết quả của sự tương tác giữa ngữ nghĩa của các từ ngôn ngữ với dữ liệu.
- Chưa có cơ chế hình thức đánh giá tính khái quát và tính cụ thể của các từ ngôn ngữ và bài toán thiết kế các thể hạt (granularity) cho các phân hoạch mờ trên miền các thuộc tính đảm bảo sự cân bằng giữa tính khái quát và tính cụ thể của các từ ngôn ngữ chưa được đặt ra.
1.3. Đại số gia tử
1.3.1. Đại số gia tử của biến ngôn ngữ
Định nghĩa 1.4. [50] Giả sử X là một biến ngôn ngữ có miền giá trị là Dom(X). Một ĐSGT AX tương ứng của X là một bộ 5 thành phần AX = (X, G, C, H, ≤), trong đó: (X,
≤) là cấu trúc dựa trên quan hệ thứ tự, X là một tập giá trị ngôn ngữ của X với X Dom(X) và ≤ là quan hệ thứ tự được cảm sinh bởi ngữ nghĩa vốn có của các từ ngôn ngữ trên X; G = {c-, c+} là tập các phần tử sinh có quan hệ ngữ nghĩa c- ≤ c+, trong đó c- và c+ tương ứng là phần tử sinh nguyên thủy âm và dương; C = {0, W, 1} là tập các hằng thỏa quan hệ ngữ nghĩa 0 ≤ c- ≤ W ≤ c+ ≤ 1, trong đó 0 và 1 tương ứng là phần tử nhỏ nhất và phần tử lớn nhất trong cấu trúc (X, ≤), W là phần tử trung hòa; H là tập gia tử của biến ngôn ngữ X. □
Với mỗi x X, ký hiệu H(x) là tập tất cả các giá trị ngôn ngữ u X được cảm sinh từ x bởi các gia tử trong H và được biểu diễn bởi chuỗi u = hn…h1x, với hn, …, h1 H. Trong
trường hợp x {c-, c+} thì chuỗi u = hn…h1c được gọi là một biểu diễn chính tắc nếu hj+1…h1c ≠ hj…h1c với mọi j = 1, …, n - 1 và khi đó u có độ dài n + 1, được ký hiệu là |u|
hoặc l(u). Ký hiệu sau: Xk là tập tất cả các giá trị ngôn ngữ có độ dài đúng bằng k và X(k) là tập tất cả các giá trị ngôn ngữ có độ dài nhỏ hơn hoặc bằng k.
Trong ĐSGT AX = (X, G, C, H, ≤) nếu X, G và H là tập sắp thứ tự tuyến tính thì AX được gọi là ĐSGT tuyến tính. Một số tính chất của ĐSGT:
- Dấu của c+ là sign(c+) = +1, dấu của c- là sign(c-) = -1.
- Tập các gia tử dương là H+ = {hj: 1 ≤ j ≤ p} và có dấu sign(hj) = +1, tập các gia tử là H- = {hj: -q ≤ j ≤ -1} và có dấu sign(hj) = -1 và ta có H = H+ H-.
- Gia tử k là dương đối với gia tử h nếu k làm tăng ngữ nghĩa của h và khi đó dấu sign(k, h) = +1. Ngược lại, k là âm đối với h nếu k làm giảm ngữ nghĩa của h và có dấu sign(k, h) = -1. Dấu của một hạng từ x với x = hmhm-1…h2h1c, trong đó c {c-, c+} và hj H, được tính như sau:
Sign(x) = sign(hm, hm-1) × … × sign(h2, h1) × sign(h1) × sign(c). (1.16) Ý nghĩa của dấu của từ là: nếu sign(hx) = +1 thì x ≤ hx, và nếu sign(hx) = -1 thì hx ≤ x.
- Tính kế thừa trong cảm sinh các giá trị ngôn ngữ của các gia tử. Khi một giá trị ngôn ngữ hx được cảm sinh từ x bằng việc tác động gia tử h vào x thì ngữ nghĩa của hx thay đổi nhưng vẫn truyền đạt ngữ nghĩa gốc của x. Tính chất này góp phần bảo toàn quan hệ thứ tự ngữ nghĩa: nếu hx ≤ kx thì h’hx ≤ k’kx, hay h’ và k’ bảo tồn quan hệ ngữ nghĩa của hx và kx một cách tương ứng.
Hai từ ngôn ngữ x và y được gọi là độc lập nếu x H(y) và y H(x).
Một ĐSGT AX được gọi là tự do nếu với mọi x H(G) thì hx ≠ x. Nghĩa là AX là tự do nếu và chỉ nếu chỉ có các hằng tử là các phần tử bất động.
Định lý 1.1. [50] Cho tập H- và H+ là các tập sắp thứ tự tuyến tính của ĐSGT AX = (X, G, C, H, ≤). Khi đó ta có các khẳng định sau:
(1) Với mỗi u X thì H(u) là tập sắp thứ tự tuyến tính.
(2) Nếu X được sinh từ G bởi các gia tử và G là tập sắp thứ tự tuyến tính thì X cũng là tập sắp thứ tự tuyến tính. Hơn nữa nếu u < v, và u, v là độc lập với nhau, tức là u H(v) và v H(u), thì H(u) H(v). □
1.3.2. Lượng hóa đại số gia tử
Xét bất kỳ ánh xạ υ của một ĐSGT AX đảm bảo tính bảo toàn cấu trúc thứ tự trên miền giá trị của X. Đẳng cấu υ đảm bảo việc cảm sinh ánh xạ của mọi mô hình tính mờ
H(x) của một từ ngôn ngữ x tới một khoảng nằm trong đoạn [0, 1], được gọi là khoảng tính mờ của x và được ký hiệu là (x). Độ dài của (x) được gọi là độ đo tính mờ của x và được ký hiệu là fm(x). Với ý tưởng trên, độ đo tính mờ được tiên đề hóa như sau:
Định nghĩa 1.5. [52, 53] Một hàm fm: X [0, 1] được gọi là một độ đo tính mờ của biến ngôn ngữ X, nếu nó có các tính chất sau:
(FM1) fm là một độ đo đầy đủ trên X, nghĩa là fm(c) + fm(c+) = 1 và, u X,
h∈H
∑
fm(hu)=fm(u)
;
(FM2) Nếu H(x) = x, thì fm(x) = 0. Đặc biệt ta có: fm(0) = fm(W) = fm(1) = 0;
(FM3) x, y X, h H, ta có fm(hx)/x = fm(hy)/y, nghĩa là tỷ số này không phụ thuộc vào một phần tử cụ thể nào trong X mà chỉ phụ thuộc vào h được gọi là độ đo tính mờ của gia tử h và được ký hiệu là (h). □
Công thức tính đệ quy độ đo tính mờ của x = hm...h1c với c {c-, c+} như sau:
fm(x) = (hm)...(h1) fm(c), trong đó h H( ) 1h
. (1.17)
Mệnh đề 1.1. [52, 53] Độ đo tính mờ fm của các khái niệm và (h) của các gia tử thỏa:
1) fm(hx) = (h)fm(x), x X;
2) fm(c) + fm(c+) = 1;
3)
∑
i=−q,i≠0 p
fm(hic)=fm(c)
, với c {c, c+};
4)
∑
−q≤i≤p,i≠0
fm(hix)=fm(x)
, x X.
5)
1
( )i
i q
h
và
∑
i=1 p
μ(hi)=β
, với , > 0 và + = 1. □
Định nghĩa 1.6. [52, 53] Ngữ nghĩa số của các từ ngôn ngữ hay ánh xạ định lượng ngữ nghĩa của AX là ánh xạ bảo toàn thứ tự υ: X [0,1] thỏa mãn các điều kiện sau:
SQM1) υ bảo toàn thứ tự trên X, tức là x < y υ(x) < υ(y) và υ(0) = 0, υ(1) = 1;
SQM2) υ là song ánh và ảnh của X, υ(X), là trù mật trong đoạn [0, 1] ; □
Mệnh đề 1.2. [52, 53] Ánh xạ định lượng ngữ nghĩa υ được xác định quy nạp như sau:
1) υ(W) = = fm(c), υ(c) = - fm(c), υ(c+) = +fm(c+);
2) υ(hjx) = υ(x)+ Sign(hjx)(
∑
i=1j fm(hix)−ω(hjx)fm(hjx)) , với 1 j p, và υ(hjx) = υ(x)+ Sign(hjx)(∑
i=−1j fm(hix)−ω(hjx)fm(hjx)) , với q j 1.Hai công thức này có thể viết thành một công thức chung, với j [-q^p] và j 0 là:
(h xj ) ( )x Sign h x( j )( i sign jj ( ) fm h x( i ) (h x fm h xj ) ( j ))
, vàω(hjx)=1
2[1+Sign(hjx)Sign(hphjx)(β−α) ]∈{α , β}
. □ 1.3.3. Ý nghĩa ứng dụng của đại số gia tử
ĐSGT đã được ứng dụng thành công trong các lĩnh vực như điều khiển mờ, hồi quy và dự báo, thiết kế FLRBC, ... Trong những ứng dụng như vậy, ngữ nghĩa của các từ ngôn ngữ được sử dụng trong biểu diễn các luật ngôn ngữ mờ cần được biểu thị bằng tập mờ
phù hợp với ngữ nghĩa vốn có của chúng. Với độ đo tính mờ của |H| - 1 gia tử, độ đo tính mờ của một phần tử sinh (fm(c-) hoặc fm(c+)) và một số nguyên dương k giới hạn độ dài tối đa của các từ ngôn ngữ được gọi là các tham số ngữ nghĩa, ký hiệu là Л. Khi cho một bộ
giá trị cụ thể của các tham số ngữ nghĩa, các giá trị định lượng của các từ ngôn ngữ được tính toán và ngữ nghĩa tính toán dựa trên tập mờ của chúng được xây dựng. Giá trị định lượng của mỗi từ ngôn ngữ là một điểm nằm trong khoảng tính mờ liên kết với độ đo tính mờ tương ứng xác định đỉnh của tập mờ tam giác. Như vậy, ngữ nghĩa tính toán dựa trên tập mờ của các từ ngôn ngữ được tích hợp với nhau dựa trên cơ chế hình thức hóa chặt chẽ, trong đó các tham số tính mờ của ĐSGT sinh ra các tập mờ tam giác của tất cả các từ ngôn ngữ của ĐSGT hay biến ngôn ngữ. Nghĩa là các đại lượng xác định các tập mờ bị ràng buộc với nhau và có thể được hiệu chỉnh thích nghi nhờ các tham số tính mờ.
1.3.4. Những vấn đề tồn tại
Trong lý thuyết ĐSGT AX mới chỉ sử dụng giá trị định lượng ngữ nghĩa điểm, tức lõi ngữ nghĩa điểm, nên phần tử trung hòa W và hai phần tử 0 và 1 không có lõi. Điều này đồng nghĩa với độ đo tính mờ của chúng được quy ước bằng 0 mặc dù trong các ứng dụng thực tế đều thường xây dựng các tập mờ cho chúng.
Do ngữ nghĩa của từ ngôn ngữ chứa một miền có giá trị phù hợp với ngữ nghĩa của từ nhất nên tập mờ biểu diễn ngữ nghĩa của từ phải có lõi là một khoảng. Tuy nhiên, lý thuyết ĐSGT AX với giá trị định lượng ngữ nghĩa điểm chỉ sinh được các tập mờ tam giác.
Luận án mong muốn xây dựng một cơ sở hình thức cho việc sinh tự động ngữ nghĩa dựa trên tập mờ hình thang từ ngữ nghĩa vốn có của các từ trên cơ sở phát triển mở rộng ĐSGT biểu diễn lõi ngữ nghĩa của các từ ngôn ngữ và ứng dụng giải bài toán thiết kế FLRBC.
1.4. KẾT LUẬN CHƯƠNG 1
Trong chương này, luận án đã hệ thống lại những kiến thức cơ sở liên quan đến các hệ dựa trên luật ngôn ngữ mờ, đại số gia tử và khả năng ứng dụng.
CHƯƠNG 2
LÕI NGỮ NGHĨA VÀ NGỮ NGHĨA HÌNH THANG CỦA KHUNG NHẬN THỨC NGÔN NGỮ VÀ ỨNG DỤNG GIẢI BÀI TOÁN PHÂN LỚP
2.1. MỞ RỘNG ĐSGT CHO VIỆC MÔ HÌNH HÓA LÕI NGỮ NGHĨA CỦA CÁC TỪ NGÔN NGỮ
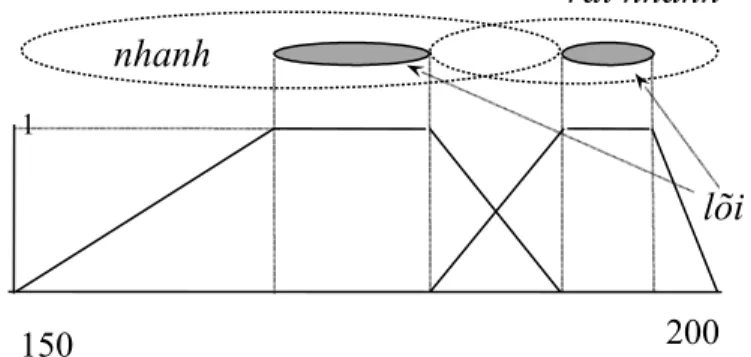
Hình 2.1. Mối quan hệ giữa từ “nhanh” và “rất nhanh” của biến ngôn ngữ TOCDO và các giá trị của tập nền U được biểu diễn dưới dạng các tập mờ.
1
200 150
rất nhanh nhanh
lõi
Mọi từ mang ngữ nghĩa không rõ ràng x của một biến ngôn ngữ với miền tham chiếu số U biểu diễn mối quan hệ của x với các giá trị của U, tức là mọi giá trị số của U phù hợp với x ở một độ chắc chắn nhất định. Mối quan hệ giữa từ “nhanh” và “rất nhanh” của biến ngôn ngữ TOCDO và các giá trị của U có thể được biểu diễn dưới dạng các tập mờ như trong Hình 2.1. Ký hiệu Core(x) là lõi ngữ nghĩa của của x thì Core(x) = {u: x(u) = 1} và ngữ nghĩa của x là tập Sem(x) = {u: x(u) (0, 1]}. Lõi ngữ nghĩa của hai từ ngôn ngữ bất kỳ x, y X và ngữ nghĩa tương ứng của chúng thỏa các điều kiện sau:
(C1) Core(x) Sem(x);
(C2) Nếu x ≤ y thì Core(x) ≤ Core(y), Core(x) ≤ Sem(y) và Sem(x) ≤ Core(y).
Trong phương pháp hình thức hóa ĐSGT, lõi ngữ nghĩa của từ ngôn ngữ x cần được sinh từ gia tử nên một gia tử nhân tạo h0 được bổ sung nhằm cảm sinh lõi ngữ nghĩa của x là h0x. Việc mở rộng một ĐSGT tuyến tính AX được thực hiện như sau.
Định nghĩa 2.1. Mở rộng ngữ cảnh của một ĐSGT tuyến tính và tự do AX = (X, C, G, H,
) là ĐSGT mở rộng AXmr = (Xmr, C, G, Hmr, ), trong đó C cũng là tập các hằng tử của AXmr, Hmr = HI {h0} = H+ H {I, h0}, ở đó H = {h-q, …, h-2, h-1}, h-q < ... < h-2 < h- 1 và H+ = {h1, h2 ,... , hp}, h1 < h2 < ... < hp, nghĩa là HI = H {I}, Xmr = X {h0x | x X}
và ≤ là quan hệ thứ tự mở rộng của X trên Xmr, nếu nó thỏa các tiên đề sau:
(A1) Toán tử đơn vị V trong H+ là dương hoặc âm đối với đối với mọi gia tử trong H.
Chẳng hạn V là dương đối với chính nó và đối với L trong H-.
(A2) Nếu u, v X là độc lập, tức là u HI(v) và v HI(u) thì x HI(u) x HI(v).
(A3) Kế thừa gia tử: Với x X, h, k, h’, k’ H, ta có:
(i) x ≠ hx x HI(hx).
(ii) h ≠ k & hx kx h’hx k’kx.
(iii)hx ≠ kx thì hx và kx là độc lập.
(A4) u X, nếu v HI(u) và v u (v ≥ u) thì v hu (v ≥ hu) với h HI. (A5mr) Các tiên đề cho lõi ngữ nghĩa của từ ngôn ngữ: với x, y Xmr và x ≠ y,
(i) hh0x = h0x với h Hmr và với x X, h0x = x khi và chỉ khi x là hằng, ngược lại x và h0x là không sánh được.
(ii) Với ∀x , y∈X , x<y⟹h0x<y∧x<h0y . □
Các tiên đề của AXmr được bổ sung nhằm mục đích mô tả các đặc trưng của lõi ngữ nghĩa của các từ ngôn ngữ dưới dạng quan hệ thứ tự.
Định lý 2.1. Cho AXmr = (Xmr, C, G, Hmr, ) là một ĐSGT mở rộng của một ĐSGT tuyến tính và tự do AX = (X, C, G, H, ). Khi đó,
(i) Xmr = X {h0x: x X \ C } và với x C, h0x X.
(ii) x, y Xmr, x ≠ y, ta có x<y⟺x<h0y⟺h0x<y⟺h0x<h0y . Vì vậy tập {h0x: x X} được sắp tuyến tính.
(iii)Tập Xkmr
=Xk∪{h0u:u∈X(k−1)} được sắp tuyến tính. □
Định lý sau khẳng định các tiên đề từ (A2) đến (A4) vẫn đúng đối với AXmr .
Định lý 2.2. Cho AXmr = (Xmr, C, G, Hmr, ) là một ĐSGT mở rộng của một ĐSGT tuyến tính và tự do AX = (X, C, G, H, ). Nếu các tập X và H xuất hiện trong các tiên đề (A2), (A3), (A4) được thay thế tương ứng trong bởi Xmr và Hmr thì các mệnh đề được ký hiệu tương ứng là (A2mr), (A3mr), (A4mr) vẫn đúng đối với AXmr. □
Định lý 2.3. Mọi từ ngôn ngữ được cảm sinh từ AXmr có biểu diễn chính tắc duy nhất. □ 2.2. MỞ RỘNG KHÁI NIỆM ĐỘ ĐO TÍNH MỜ
Để bảo đảm tính linh hoạt trong ứng dụng, ta giả thiết độ đo tính mờ của phần tử trung hòa W là khác 0, tức fm(W) ≠ 0. Khi đó, hệ tiên đề của độ đo tính mờ mở rộng của AXmr được phát biểu như sau:
Định nghĩa 2.2. Cho AXmr = (Xmr, C, G, Hmr, ) là một ĐSGT mở rộng của một ĐSGT tuyến tính và tự do AX. Một hàm fm : Xmr [0,1] được gọi là độ đo tính mờ của ĐSGT AXmr nếu nó thỏa các tính chất sau:
(fm1) fm(c-) + fm(W) + fm(c+) = 1;
(fm2) hHmr fm(hu) = fm(u), uH(G);
(fm3) h Hmr và x, y H(G) thỏa x, y ≠ h0z thì
fm(hx)
fm(x) =fm(hy) fm(y) . □
Tỷ số fm(hx)/fm(x) là không phụ thuộc vào x được gọi đó là độ đo tính mờ của gia tử h và ký hiệu là (h) và h bao gồm cả h0.
Mệnh đề 2.1. Độ đo tính mờ fm của các từ ngôn ngữ của ĐSGT AXmr được định nghĩa như trong Định nghĩa 2.2 thỏa các tính chất sau:
(1) fm(hx) = (h)×fm(x) với h Hmr, x H({c, c+}) và hx ≠ x;
(2) fm(x) = (hn)×...×(h1)fm(c), với x = hn...h1c, c {c, c+} là biểu diễn chính tắc của x Xmr;
(3)
h H mr( ) 1h ;(4)
∑
x∈X(k−1)
fm(h0x)+
∑
x∈Xk
fm(x)=1 với ∀k>0 . Với k = 1, ta có (fm1). □ 2.3. HỆ KHOẢNG TÍNH MỜ LIÊN KẾT VỚI ĐỘ ĐO TÍNH MỜ
Gọi PI([0, 1]) là tập tất cả các khoảng con của đoạn [0, 1]. Ta luôn luôn quy ước là các khoảng đều đóng ở đầu mút trái và mở ở đầu mút phải, trừ khi đầu mút phải là giá trị 1. Ta có khái niệm khoảng tính mờ của các từ ngôn ngữ của Xmr, (x) với
x∈X(kmr)={x∈Xmr:|x|≤ k}=X(k)∪{h0x:x∈X(k−1)} , dựa trên hệ tiên đề của độ đo tính mờ:
Định nghĩa 2.3. Cho một ĐSGT mở rộng AXmr = (Xmr, C, G, Hmr, ) của một ĐSGT tuyến tính và tự do AX và độ đo tính mờ fm: Xmr [0, 1] thỏa các tính chất trong Định nghĩa 2.2. Giả sử mỗi từ ngôn ngữ x X(k)
mr được liên kết với một khoảng trong PI([0, 1]). Các khoảng này được gọi là các khoảng tính mờ mức k của các từ ngôn ngữ tương ứng của AXmr và nó được xây dựng quy nạp theo k như sau:
1) Với k = 1, xây dựng các khoảng tính mờ 1(c-), 1(W), 1(c+) với |1(x)| = fm(x), sao cho chúng có thứ tự tương đồng với thứ tự của các hạng từ c-, W, c+.
2) Với k > 1 và xC, xây dựng các khoảng tính mờ k(x) sao cho (i) nếu |x| < k - 1 thì |
k(x)| = |k-1(x)|, (ii) nếu |x| = k - 1 thì |k(x)| = (h0)fm(x), (iii) nếu |x| = k thì |k(x)| = fm(x), (iv) thứ tự của các khoảng tính mờ tương đồng với thứ tự của các hạng từ x, tức là, với x, y {hx: h Hmr}, nếu x ≤ y thì k(x) ≤ k(y). □
Thuật toán 2.1. Thuật toán xây dựng hệ khoảng tính mờ.
Đầu vào: Các độ đo tính mờ fm(c-), fm(W), (h) với h Hmr và số k >= 1 xác định độ dài tối đa của các từ ngôn ngữ. Lưu ý: fm(c+) = 1 - fm(c-) - fm(W).
Đầu ra: là tập các khoảng với nhãn là các từ ngôn ngữ trong X(k)mr
. Begin
Khởi tạo j = 1 và tập bằng rỗng.
Bước 1: Với j = 1, ta có = 1(c-) 1(W) 1(c+), trong đó:
1(c-) = [0, fm(c-)), 1(W) = [fm(c-), fm(c-)+ fm(W)), 1(c+) = [fm(c-) + fm(W), 1].
Nếu k = 1 thì dừng, ngược lại nếu k > 1 thì thực hiện Bước 2.
Bước 2: j = j + 1. Với mỗi từ ngôn ngữ x X(j−1)
mr thực hiện:
(i) Nếu |x| < j – 1 thì ta có = j(x) với j(x) = j-1(x) .
(ii) Nếu từ ngôn ngữ x thỏa |x| = j – 1 thì:
Nếu Sign(max(Hmr)) = 1 thì lặp l = 1 đến |Hmr| và đặt i = l, ngược lại thì lặp l = |Hmr| giảm đến 1 và đặt i = |Hmr| – l + 1, để tính các khoảng tính mờ mức j cho các từ hix được sinh ra từ x với hi Hmr.
Nếu i = 1, j(hix) = [L(j-1(x)), L(j-1(x)) + (hi)|j-1(x)|), ngược lại nếu i > 1 thì, Đặt Km = R (j(hi-1x)) + (hi)|j-1(x)|. Nếu Km = 1 thì j(hix) = [R (j(hi-1x)), Km), ngược lại thì j(hix) = [R (j(hi-1x)), 1] (đóng phải).
= j(hix).
Bước 3 (bước lặp): Lặp lại Bước 2 cho đến khi j = k.
Trả lại là tập các khoảng với nhãn là các từ ngôn ngữ trong X(k)mr
. End.
Ký hiệu L(•) và R (•) là điểm mút trái và mút phải của một khoảng bất kỳ.
Kết thúc thuật toán, ta thu được là tập các khoảng với nhãn là các từ trong X(k)
mr .
Định lý 2.4. Thuật toán 2.1 về xây dựng các khoảng tính mờ là đúng đắn và các khoảng tính mờ của X(k)
mr có các tính chất sau:
(1) Với mỗi x thỏa |x| = k, khoảng tính mờ mức k của x, k(x), thỏa |k(x)| = fm(x), còn với x mà |x| < j k, k(x) = I(h0x) và |k(x)| = (h0)fm(x), tức là các hạng từ độ dài ngắn hơn j có mặt trong ngữ cảnh cùng các hạng từ độ dài j sẽ có ngữ nghĩa bị co lại;
(2) Với mọi x X(k)mr thỏa |x| = j < k, ta có k(x) = I(h0x) và |k(x)| = (h0)fm(x). Với x thỏa |x| = j k – 2, ta có k(x) = k-1(x).
(3) Tập tất cả các khoảng tính mờ mức k, FI(k) = {k(x), x X(k)
mr }, có các tính chất:
a- Đối với hạng từ hằng W, ta có k(W) = 1(W);
b- Với mỗi x H({c,c+}) thỏa |x| = k – 1, tập các khoảng tính mờ {k(hx): h Hmr} là một phân hoạch nhị phân của khoảng tính mờ k-1(x) mức k – 1 của x.
c- Các khoảng tính mờ trong FI(k) có thứ tự tương đồng với thứ tự của các hạng từ của chúng và lập thành một phân hoạch nhị phân của đoạn [0,1]. □
2.4. ÁNH XẠ ĐỊNH LƯỢNG NGỮ NGHĨA KHOẢNG
Định nghĩa 2.4. Cho AXmr là ĐSGT mở rộng của AX tuyến tính và tự do, ánh xạ f : Xmr
PI([0, 1]) được gọi là ánh xạ định lượng ngữ nghĩa khoảng của AXmr nếu nó thỏa các điều kiện sau:
(IQ1) f bảo toàn thứ tự trên Xmr, tức là nếu x y thì f(x) f(y), với x, y Xmr; (IQ2) f(Xmr) là tập trù mật trong [0, 1]. □
Định lý 2.5. Cho độ đo tính mờ fm của ĐSGT AXmr và là tập tất cả các khoảng tính mờ
của các từ ngôn ngữ của AXmr được xác định bởi fm. Khi đó ánh xạ f: Xmr PI[0, 1]
được định nghĩa như sau là ánh xạ định lượng ngữ nghĩa khoảng:
f(x) = |x|+1(h0x) PI[0, 1], với x, y Xmr (2.5) với lưu ý rằng, nếu x = h0z thì f(x) = |x|+1(h0x) = |x|(h0z). □
2.5. MỞ RỘNG ĐỘ ĐO TÍNH MỜ CỦA CÁC PHẦN TỬ 0 VÀ 1
ĐSGT mở rộng AXmr được mở rộng thành ĐSGT mở rộng toàn phần với độ đo tính mờ của hai phân tử 0 và 1 khác 0 và được ký hiệu là AXmrtp. Khi đó, hệ tiên đề của độ đo tính mờ mở rộng của AXmrtp được phát biểu như sau:
Định nghĩa 2.5. Cho một ĐSGT mở rộng toàn phần AXmrtp = (Xmr, C, G, Hmr, ) của một ĐSGT mở rộng tự do AXmr. Một hàm fm : Xmr [0,1] được gọi là độ đo tính mờ của ĐSGT AXmrtp nếu nó thỏa các tính chất sau:
(fmc1) fm(0) + fm(c-) + fm(W) + fm(c+) + fm(1) = 1;
(fmc2) hHmr fm(hu) = fm(u), uH(G);
(fmc3) h Hmr và x, y H(G) thỏa x, y ≠ h0z thì fm(hx)/fm(x) = fm(hy)/fm(y). □ Từ Định lý 2.4, điểm mút trái của f(x) qua các độ đo tính mờ với k = |x| được tính:
L(f(x)) =
∑
y∈Xk+1∧y<x
fm(y)+
∑
y∈X(k)∧y<x
fm(h0 y) . (2.6)
Công thức (2.6) chưa thể hiện mối quan hệ giữa giá trị định lượng và các tham số của từ. Định lý sau cung cấp công thức đệ quy tính L(f(x)). Giả sử H+ = {hj: j = 1, …, p}, H- = { hj: j = -1, …, -q}, β=
∑
j=1 p
μ(hj) và α=
∑
j=−1
−q
μ(hj) . Ta có, α+β+μ(h0)=1 .
Định lý 2.6. Điểm mút trái của giá trị định lượng f được cảm sinh bởi các độ đo tính mờ
fm được tính đệ quy theo thủ tục sau:
(1) Với các từ có độ dài 1: L(f(0)) = 0, L(f(c-)) = fm(0) + × fm(c-), L(f(W)) = fm(0) + fm(c-), L(f(c+)) = fm(0) + fm(c-) + fm(W) và L(f(1)) = 1 - fm(1).